This node allows you to merge two input data streams into one output data stream. The merge is performed on a row-per-row basis or by key merge performing a left-outer-join. The method is determined on what input columns are fed into the merge node.
- Data Columns section allows you to analyse what input data columns are incomming into the node. You must have two nodes feeding into the Merge node.
- Input 1 section shows what columns are fed into the Merge node for the first connected input.
- Input 2 section shows what columns are fed into the Merge node for the second connected input.
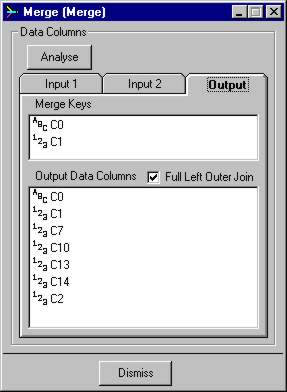
- Output section shows what columns will be fed out of the node and also shows how the merge will be performed.
- The Merge Keys shows the columns that are common between the Input 1 and 2 columns, they must match by name and type. If there are columns listed here then a Merge is performed using the left-outer-join method otherwise a row-per-row merge is performed.
- The Full Left Outer Join option is only activated when a merge by keys is performed. It allows you to specify whether the rows from Input 1 are passed to the output when there is no match found with Input 2 rows based on the Merge Keys. The output row will contain all the data for columns in Input 1 and the remaining columns will be outputed with the missing data sysmbol '?'. If this option is not selected then the Input 1 rows that are not matched to the Input 2 rows are not outputed.
- The Output Data Columns shows the list of columns been outputed from the node. All the Input 1 columns are included first in the list followed by the Input 2 columns that are not common with Input 1 columns.
NOTE 1: If there are no Merge Key columns then a row-per-row merge is performed. If Input 1 has 100 rows and Input 2 has 110 rows, then the output will consist of 110 rows where the data for columns in Input 1 will be padded with missing data '?' for the last 10 rows. The same goes if Input 2 has less rows than Input 1.
NOTE 2: If there are columns from Input 1 and 2 with a common name but different type then the Analyse will fail. You will have to change the name or type of the column in Input 2 to match the one in Input 1 or vise versa.
NOTE 3: The Merge by Keys can be a memory exhausting process, so choose your Merge Key columns wisely. The reason been that every row in Input 1 is matched to every row in Input 2, that has matching key values, and a new row is created for the output. That is, you can have 100 rows for Input 1 and 10 rows for Input 2 which could produce 100x10=1000 rows of output if every row from Input 1 matched every row in Input 2.